-
[논문 리뷰] Editing Models with Task Arithmetic [arxiv Dec 8, 2022]Paper Review/Computer Vision 2023. 1. 9. 11:46
본 연구에서는 task vector를 제안하여, PLM을 down-stream task에 적용할때 task에 맞게 모델을 edit 하거나, biases를 mitigate, unwanted behavior를 컨트롤, 새로운 information으로 update 하는데에 이용한다.
[Github]
- https://github.com/mlfoundations/task_vectors
[Breif Summary created by ChatGPT]
- Task vectors can modify the behavior of pre-trained neural networks by specifying a direction in the weight space of the model.
- Task vectors are created by subtracting the weights of a pre-trained model from the weights of the same model after fine-tuning a task.
- Task vectors can be modified and combined through arithmetic operations, allowing the model's behavior to be steered in certain directions.
- Task vectors can be used to improve performance on multiple tasks at once, and can even improve performance on a fourth task when the tasks are linked by an analogy relationship and task vectors from three of the tasks are combined.
Forgetting via negation
특정 task에서 학습된 정보를 forget하는데에 이용. 가령, toxic 데이터에서 학습된 LM은 toxic에 관련된 keyword들을 생성할 확률이 높은데, negate vectors를 이용하면 toxic을 생성하는 확률을 낮출 수 있음. 즉, undesirable behaviors를 줄이는데에 이용할 수 있음.
Learning via addition
또한 task vectorks를 adding 함으로써 better multi-task models를 만들거나, single task에서의 성능을 improve 할 수도 있음. 이러한 방법은 in-house model이나 공개된 PLM-based fine-tuned model로부터 knowledge를 transfer 해와서 target task의 성능을 높일 수 있다는 장점이 있음.
Task analogies
마지막으로, "A is to B as C is to D"와 같이 첫 3개의 task vectors를 활용하여 소수의 학습데이터나 학습 데이터 없이 4번째 테스크의 성능을 improve 할 수도 있다 (Domain Generalization). 또한 task vectors를 활용하는 방법은 simple, fast, and effective with no extra cost at inference time in terms of memory or compute.
Task Vectors

Task Vectors, Forgetting via negation, Learning via addition, and Task analogies. $\theta_{pre}$와 $\theta_{ft}^t$가 각각 pre-trained and fine-tuned 모델의 parameter라고 하면, task vector는 아래와 같이 element-wise differene로 정의된다.
$$\tau_t = \theta_{ft}^t - \theta_{pre}.$$
또한 본 연구에서는, 목적에 따라 negating a task vector, adding task vectors together, combining task vectors와 같이 3가지의 vector 연산을 사용하는데 해당 벡터들은 아래와 같이 정의된다.
Negating a task vector
Extrapolating between the fine-tuned model and the pre-trained model. 해당 연산을 수행한 모델은 target task에 대한 성능이 낮아짐 (with little change in performance on control tasks).
$$\tau_{new}=-\tau$$

실험 결과를 살펴보면, baseline (Gradient ascent, Random vector)과 비교하였을때, Control accuracy의 성능 손실을 최소화하면서 target task의 성능을 낮출 수 있는것을 확인할 수 있다. 또한 Table2의 toxic generation task에서의 결과를 살펴보면, fine-tuned된 모델보다 toxic generation percentage가 매우 감소하는것을 확인할 수 있고, gradient ascent 방식대비 perplexity의 손실도 거의 일어나지 않는것을 확인할 수 있다.
Adding a task vector
2개 이상의 task들을 합쳐서 multi-task model의 성능을 잘 보장하고 싶을때 다음과 같은 연산을 수행할 수 있음.
$$\tau_{new}=\Sigma_i\tau_i$$
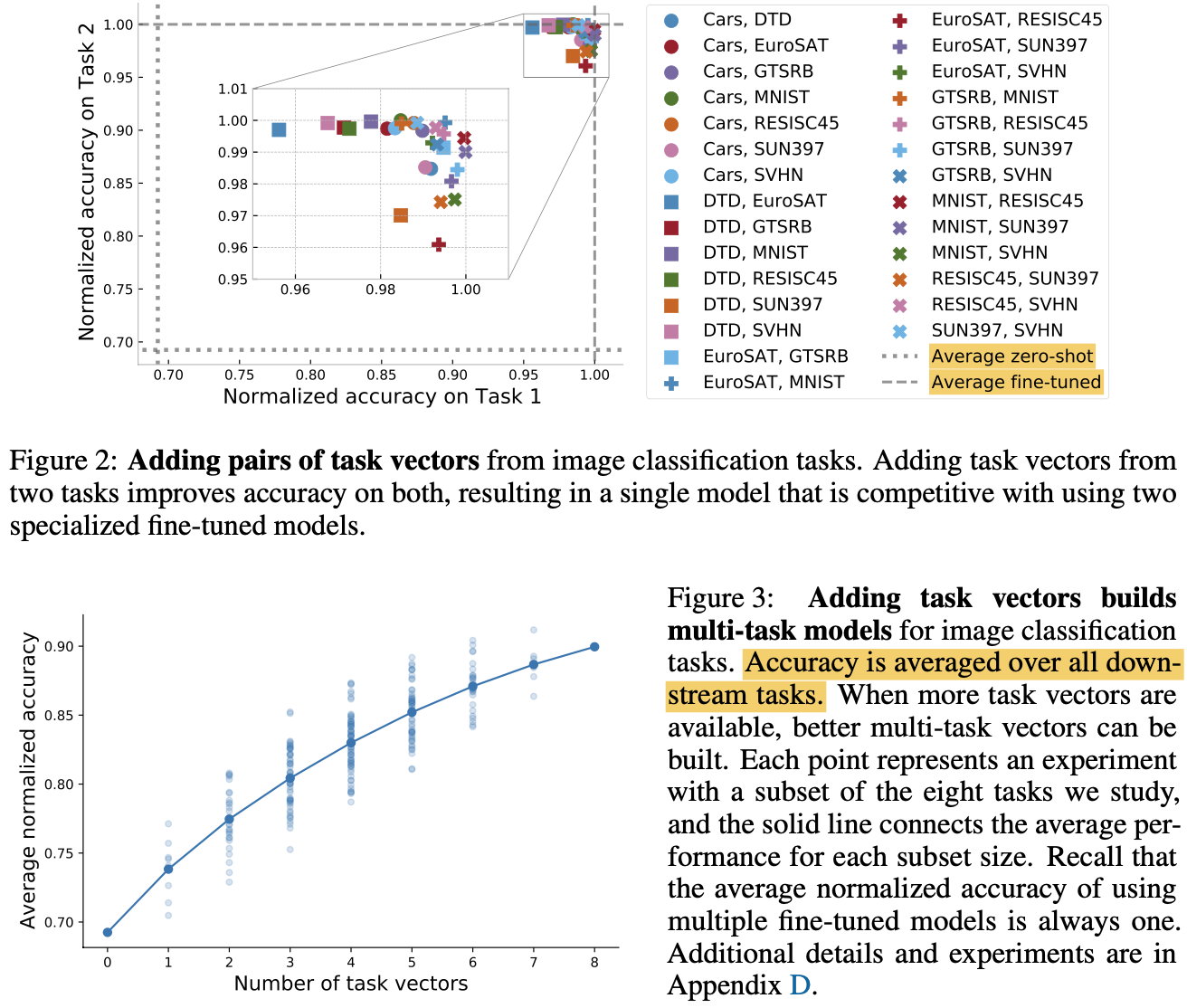
Combining task vectors
"A is to B as C is to D"와 같이 task들 간의 analogy를 고려할때 다음과 같은 연산이 활용될 수 있음.
$$\tau_{new}=\tau_C + (\tau_B - \tau_A)$$
'Paper Review > Computer Vision' 카테고리의 다른 글